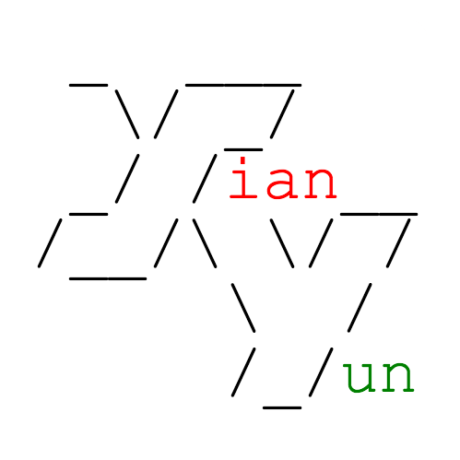
SQL LIKE 查询的一个问题
在做用户管理的时候,用户表(users) 有一个字段(dept)用来存储用户所在部门的信息, 字段的值一般是这样的,各级部门间使用横杠分隔:
我们的系统有一个根据用户所在部门进行过滤的功能,所以我们用了类似下面的查询语句:
这样的性能还好,但是今天发现一个问题是,当有两个部门名称很相似,比如:
这时在查询 XX宝CEO 的时候就会把 XX宝-CEO办公室 的用户也查询出来。
于是想到正则表达式:
合并正则表达式的另一解:
杯具的性能问题。
突然想到
于是简单有效的解决了这个问题。
Tags: SQL
Published on 2010-08-13